Introduction to Reinforcement Learning
Learning
All animals and automata exhibit some kind of behavior; they do something in response to the inputs that they receive from the environment they exist in. Some animals and automata change the way the behave over time; given the same input, they may respond differently later on than they did earlier on. Such agents learn. The field of machine learning studies learning algorithms, which specify how the changes in the learner's behavior depend on the inputs received and on feedback from the environment.
Learning algorithms fall into three groups with respect to the sort of feedback that the learner has access to. On the one extreme is supervised learning: for every input, the learner is provided with a target; that is, the environment tells the learner what its response should. The learner then compares its actual response to the target and adjusts its internal memory in such a way that it is more likely to produce the appropriate response the next time it receives the same input. We can think of learning a simple categorization task as supervised learning. For example, if you're learning to recognize the sounds of different musical instruments, and you're told each time what the instrument is, you can compare your own response to the correct one.
On the other extreme is unsupervised learning: the learner receives no feedback from the world at all. Instead the learner's task is to re-represent the inputs in a more efficient way, as clusters or categories or using a reduced set of dimensions. Unsupervised learning is based on the similarities and differences among the input patterns. It does not result directly in differences in overt behavior because its "outputs" are really internal representations. But these representations can then be used by other parts of the system in a way that affects behavior. Unsupervised learning plays a role in perceptual systems. Visual input, for example, is initially too complex for the nervous system to deal with it directly, and one option is for the nervous system to first reduce the number of dimensions by extracting regularities such as tendencies for regions to be of constant color and for edges to be continuous.
A third alternative, much closer to supervised than unsupervised learning, is reinforcement learning: the learner receives feedback about the appropriateness of its response. For correct responses, reinforcement learning resembles supervised learning: in both cases, the learner receives information that what it did is appropriate. However, the two forms of learning differ significantly for errors, situations in which the learner's behavior is in some way inappropriate. In these situations, supervised learning lets the learner know exactly what it should have done, whereas reinforcement learning only says that the behavior was inappropriate and (usually) how inappropriate it was. In nature, reinforcement learning is much more common than supervised learning. It is rare that a teacher available who can say what should have been done when a mistake is made, and even when such a teacher is available, it is rare that the learner can interpret the teacher's feedback provides direct information about what needs to be changed in the learner, that is, features of the learner's nervous system. Consider an animal that has to learn some aspects of how to walk. It tries out various movements. Some work -- it moves forward -- and it is rewarded. Others fail -- it stumbles or falls down -- and it is punished with pain.
Thus while much of the focus of machine learning has been on supervised learning, if we are to understand learning in nature, we need to study unsupervised and reinforcement learning. During the workshop, we will explore one reinforcement learning algorithm in some detail.
Reinforcement Learning
To simulate the learning of real biological systems, we need to make some simplifying assumptions about our agent and its behavior. (From now on, we'll refer to our learner as an "agent" to emphasize that it's actively doing things, not just learning what to do.) We will assume that the agent's life is a Markov decision process. That is,
- The agent perceives a finite set S of distinct states in its environment and has a finite set A of distinct actions that it can perform.
- At each discrete time step t, the agent senses the current state xt, chooses a current action ut, and executes it.
- The environment responds with a reward or punishment r(xt, ut) and a new state xt+1 = T(xt, ut). Note that we need to formalize reinforcement as a number, greater for more beneficial, less for more detrimental.
- The reinforcement and next-state functions are not necessarily known to the agent, and they depend only on the current state and action. That is, before learning, the agent may not know what will happen when it takes a particular action in a particular state, but the only relevant information for deciding what action to take is the current state, which the agent does have access to.
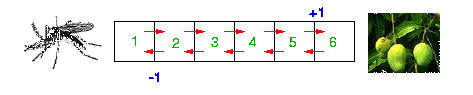
For example, consider an agent in a one-dimensional world of cells. In each cell except those on the end, the agent can go either east or west. At the extreme west end lives a swarm of mosquitoes. At the extreme east, there is a mango tree. Anywhere else, the agent receives no information at all from the environment. The agent can sense which cell it is in, but at the beginning of learning, it has no idea what cell it gets to by going east or west and what sort of reinforcement it will receive, if any. On the basis of the punishment it receives if and when it reaches the west end and the reward it receives if and when it reaches the east end, it must learn how to behave anywhere in the world.
The goal of reinforcement learning is to figure out how to choose actions in response to states so that reinforcement is maximized. That is, the agent is learning a policy, a mapping from states to actions. We will divide the agent's policy into two components, how good the agent thinks an action is for a given state and how the agent uses what it knows to choose an action for a given state.
There are several ways to implement the learning process. We will focus on just one, Q learning, a form of reinforcement learning in which the agent learns to assign values to state-action pairs. We need first to make a distinction between what is true of the world and what the agent thinks is true of the world. First let's consider what's true of the world. If an agent is in a particular state and takes a particular action, we are interested in any immediate reinforcement that's received but also in future reinforcements that result from ending up in a new state where further actions can be taken, actions that follow a particular policy. Given a particular action in a particular state followed by behavior that follows a particular policy, the agent will receive a particular set of reinforcements. This is a fact about the world. In the simplest case, the Q-value for a state-action pair is the sum of all of these reinforcements, and the Q-value function is the function that maps from state-action pairs to values. But the sum of all future reinforcements may be infinite when there is no terminal state, and besides, we may want to weight the future less than the here-and-now, so instead a discounted cumulative reinforcement is normally used: future reinforcements are weights by a value gamma between 0 and 1 (see below for mathematical details). A higher value of gamma means that the future matters more for the Q-value of a given action in a given state.
If the agent knew the Q-values of every state-action pair, it could use this information to select an action for each state. The problem is that the agent initially has no idea what the Q-values of any state-action pairs are. The agent's goal, then, is to settle on an optimal Q-value function, one which that assigns the appropriate values for all state/action pairs. But Q-values depend on future reinforcements, as well as current ones. How can the agent learn Q-values when it only seems to have access to immediate reinforcement? It learns using these two principles, which are the essence of reinforcement learning:
- If an action in a given state causes something bad to happen, learn not to do that action in that situation. If an action in a given state causes something good to happen, learn to do that action in that situation.
- If all actions in a given state cause something bad to happen, learn to avoid that state. That is, don't take actions in other states that would lead you to be in that bad state. If any action in a given state causes something good to happen, learn to like that state.
The second principle is the one that makes the reinforcement learning magic happen. It permits the agent to learn high or low values for particular actions from a particular state, even when there is no immediate reinforcement associated with those actions. For example, in our mosquito-mango world, the agent receives a reward when it reaches the east end from the cell just to the west of it. It now knows that that cell is a good one to go to because you can get rewarded in only one move from it.
What's left is the mathematical details. First, consider the optimal Q-value function, the one that represents what's true of the world.
![]()
That is, the optimal Q-value of for a particular action in a particular state is the sum of the reinforcement received when that action is taken and the discounted best Q-value for the state that is reached by taking that action. The agent would like to approach this value for each state-action pair. At any given time during learning, the agent stores a particular Q-value for each state-action pair. At the beginning of learning, this value is random or set at some default. Learning should move it closer to its optimal value. In order to do this, the agent repeatedly takes actions in particular states and notes the reinforcements that it receives. It then updates the stored Q-value for that state-action pair using the reinforcement received and the stored Q-values for the next state. Assuming the Q-values are stored in a lookup table, the agent could use one of these update equations:
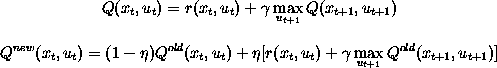
The first equation sets the Q-value to be the sum of the reinforcement received and the discounted best Q-value for the next state. But this is usually a bad idea because the information just received may be faulty for one reason or another. It is better to update more gradually, to use the new information to move in a particular direction, but not to make too strong a commitment. The second update equation reflects this strategy. There is learning rate, eta, which controls the learning step size, that is, how fast learning takes place. The new Q-value for the state and action is the weighted combination of the old Q-value for that state and action and what the new information would lead us to believe. Later we will see how a neural network can replace the lookup table for storing Q-values.
An important aspect of reinforcement learning is the constraint that only Q-values for actions that are actually attempted in states that actually occurred are updated. Nothing is learned about an action that is not tried. The upshot of this is that the agent should try a range of actions, especially early on in learning, in order to have an idea what works and what doesn't. More precisely, on any given time step, the agent has a choice: it can pick the action with the highest Q-value for the state it is in (exploitation), or it can pick an action randomly (exploration). Note that there is a tradeoff between these two strategies. Exploitation, because it is based on what the agent knows about the world, is more likely to result in benefits to the agent. On the other hand, exploration is necessary so that actions that would not be tried otherwise can be learned about. We formalize the action decision process in terms of probabilities. The simplest possibility is to flip a coin and with a certain probability exploit your knowledge (pick the action with the highest Q-value) or explore (pick a random action). A better one, which we will use, is to assign a probability to each action, basing it on the the Q-value for the action in the state. The higher an action's Q-value, the greater the probability of choosing it. But because these are still probabilities, there is still a chance of picking an action that currently has a low Q-value. It also makes sense to have the probability of exploration depend on the length of the time the agent has been learning. Early in learning, it is better to explore because the knowledge the agent has gained so far is not very reliable and because a number of options may still need to be tried. Later in learning, exploitation makes more sense because, with experience, the agent can be more confident about what it knows. The equation for the probability of choosing an action ut, then, is
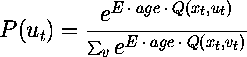
where E is a constant "exploitation rate", and the vs represent all of the possible actions in state xt. The denominator has the effect of scaling the exponential terms for each action. As the terms in the exponent increase, exploitation becomes more likely because the probabilities are more spread out. Thus as age or exploitation rate is increased, the agent is more likely to pick actions on the basis of their Q-values for the given state rather than randomly.