Check this site for the Sussex
Univ online tutorial on major topics in auditory psychophysics.
<http://www.biols.susx.ac.uk/home/Chris_Darwin/Perception/Lecture_Notes/Hearing_Index.html>
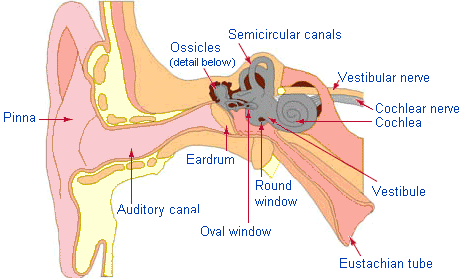
1. Anatomy and physiology of the ear.
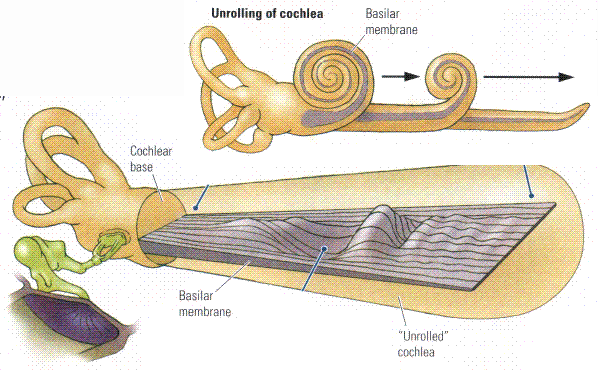
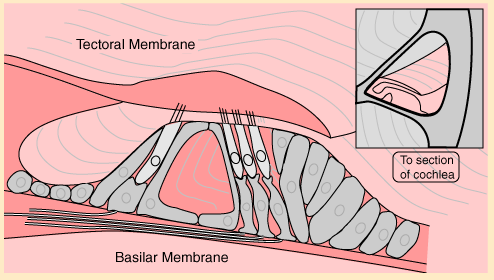
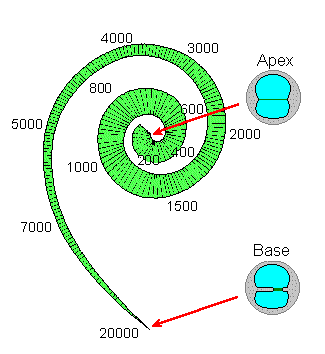
BASILAR MEMBRANE: The spiral organ within the cochlea that mechanically separates frequency components of sound. Different frequencies cause local maxima in the amplitude of the travelling wave that moves down the basilar membrane at different locations. High frequencies get maximum response at the low (early/basal) end (closest to the oval window). Low frequencies move farther down the BM. The lowest frequency with a unique location (at the very top end of the cochlea) is about 200 Hz.2. Psychophysics
Organ of Corti is a spiral structure lying on the basilar membrane the converts membrane motion into neural pulses. It is designed so that 4 rows of hair cells (one row of inner hair cells and 3 rows of outer hair cells) are mechanically disturbed by the passage of the sound wave along the BM. Each hair cell connects to a neuron that takes the signal to the central auditory system.
The Auditory Pathway is the sequence of nuclei in the brain stem leading from the cochlea to the auditory cortex in the temporal lobe of the cerebrum. The primary connections from each cochlear nucleus are to the opposite hemisphere. Each nucleus (the cochlear nucleus, superior olive, lateral leminiscus, inferior colliculus and thalamus) has a tonotopic map (or frequency-based map). Some amount of lateral inhibition appears to occur at each level.
LATERAL INHIBITION: At several locations in the lower auditory system there are `frequency maps', that is, places where each cell in a sheet of cells responds maximally to input at a particular frequency and its neighbors in one direction respond to higher fs and in the other direction to lower fs. On such a map, if each nerve cell inhibits its neighbor in proportion to its own excitation, then a blurry pattern can be sharpened. If cell A inhibits its neighbor, cell B, with value 4, and B inhibits A with value 6, then very shortly A will slow down its firing but B will continue. Thus, if there is a whole field of these with each inhibiting its neighbors on both sides for a little distance, then only the most excited cell will win in each neighborhood. This is how the gross wave motion down the BM can be sharpened up so that the peak of envelope of membrane motion is identified.
Of course, we need to hear more than one possible frequency so these neighborhoods of inhibition are small. If you have a vowel with several independent formant frequencies, then there will be multiple local peaks of activity. Thus something that is fairly similar to a sound spectrum is produced along the basilar membrane.
PLACE CODING vs TIME CODING: As noted, only frequencies above 200 Hz have unique maxima on the BM. This means that particular fibers in the auditory nerve are maximally active when their frequency is present in sound. But the mechanical action of the cochlea is such that frequencies below about 4000 Hz are transmitted directly as waveforms into the auditory nerve. That is, for low frequencies, the BM acts rather like a microphone translating mechanical pressure waves into waves of neural activation in time. This means that, between about 200 Hz and 4 kHz there is both a place code (where activity in specific fibers indicates components in the sound) and a time code (where the temporal pattern of sound waves appears as a temporal pattern of fiber activation). Below 200 Hz, there is only a temporal representation
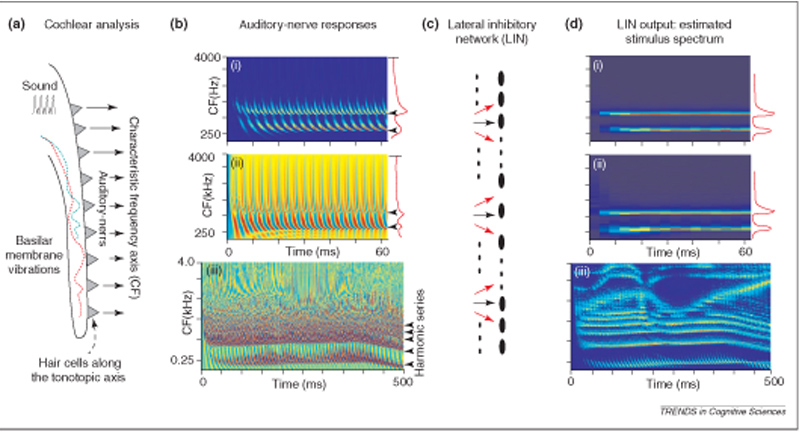
The image below from Shihab Shamma (from Trends in Cognitive Science, 2001) shows the basilar membrane on the left (a) with computationally simulated auditory nerve representation of 3 patterns in (b). The top, (i), is low intensity pattern of 300 Hz plus 600 Hz tone. Next, (ii), is the same tones but much higher intensity. The third is the phrase ``Right away'' (probably male talker). Column (c) suggests the lateral inhibitory network (in lower brainstem nuclei). Column (d) shows the estimate spectrogram available to the higher-level auditory system for analysis. Notice that both (bi) and (bii) look about the same in (d).
For the speech example, in (iii), notice that under (b), it is very difficult to interpret (even though several harmonics are pointed to by arrrows along the right edge), but in (d), you can see at least 4 distinct harmonics in the low-frequency area, as well as F2, F3 and F4 (where the harmonics are merged). Notice the F3 sweep for the [r] of right and the F2 sweep for the [wej] in away. This display shows approximately the information available to the central auditory system, that is, to area A1 and other auditory areas. Clearly it resembles a traditional sound spectrogram except that the lower frequencies region looks like `narrowband' (separating the harmonics of F0) and the higher regions look like `wideband' merging the harmonics into formants. Actual pattern recognition for identifying words is still required, of course.
There is one additional kind of shaping of the acoustic signal that Shamma left out here by choosing the specific example utterance he used. If there are abrupt acoustic onsets in the signal (like at the 3 vowel onsets of soda straw) then there is a nonlinear exaggeration of the energy onset (Delgutte and Kiang). This makes vowel onsets far more salient than the onset of high-frequency consonant energy (in syllables like so- and straw).
Psychophysics is the study of the relationship between physical stimulus properties and sensory responses of the human nervous system as reported by subjects in experimental settings. Auditory psychophysics is specifically concerned, of course, with hearing.3. Pattern Learning.
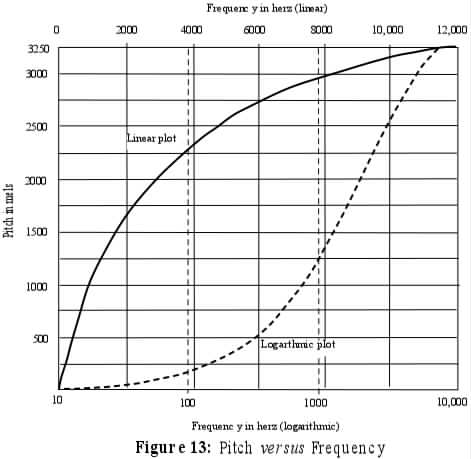
PITCH, a psychological dimension closely related to physical frequency. The relation between perceived pitch and frequency is roughly linear from 20 Hz to about 1000 Hz (thus including the range of F1 but only the lowest part of the range of F2. Thus the perceived amount of pitch change between 200 Hz and 300 Hz is about the same as the change from 800 Hz to 900 Hz. From 1000 Hz to 20 kHz, the relation is logarithmic. Thus the pitch change between 1000 Hz and 1100 Hz (a 10% difference) is about the same as the difference between 5000 Hz and 5500 Hz (also 10% although a 5 times larger change in linear Hz) and the same as 12000 Hz and 13200 (10%). An increase in frequency of 100 Hz beginning at 15 kHz, is about 1% and is just barely detectible. There are several scales that represent pitch (such as the mel scale and bark scale) where equal differences represent equal amounts of pitch change. The figure below shows mels on the vertical scale plotted against two different frequency scales. The solid line is labelled across the top in linear Hz and the dotted line is labelled across the bottom in log Hz.
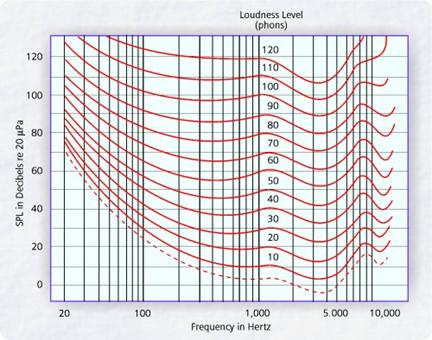
LOUDNESS is a psychological dimension closely related to physical intensity. Below is shown a graph of equal loudness contours on the plane of frequency (displayed as a log scale) against intensity (sound pressure level or dB SPL), a measure of physical energy in sound. The numbers within the graph represent `loudness levels' obtained by playing pure tones at various points in the plane and asking subjects to adjust a 1000 Hz tone to have the same perceived loudness. Notice that for both lower frequencies and very high frequencies, higher intensity is required to have the same loudness as 1000 Hz tone. (This is why you need to boost the bass on your stereo system if you turn the volume down low: otherwise the lows become inaudible.)
The significance of this graph is that only low frequencies are resolved well. At high frequencies, frequencies are scrunched together and only large differences are noticeable. Notice also that musical scales are basically logarithmic: going up one octave doubles the frequency. So the musical scale is like auditory pitch only above about 1000 Hz. Both barks and mels turn out to be interpretable in terms of linear distance along the basilar membrane. That is, listeners' judgments about amount of pitch difference are largely judgments about distaince along the basilar membrane.
.
Another issue is the neural representation of intensity differences, that is, the neural representation of acoustic dynamic range. As noted, human hearing has a dynamic range of over 100 dB. But individual neural cells rarely have more than a very small dynamic range in activation level -- between background-level firing (mean no detected signal) and maximum rate of firing. The nervous system has a variety of tricks, some quite complex, to achieve the 100 dB dynamic range.
So far, we have discussed the way sound is transformed when it is converted to neural patterns and `sent' (as they say) to the brain. Naturally, what counts is pattern recognition, and the patterns that matter for speech are primarily those due to moving articulatory gestures over time. There are neural systems that are specialized for recognition of time-varying patterns of a very general nature, and gradually, there develop neural pattern recognizers for the patterns appropriate for the environmental auditory events to which one is repeatedly exposed. This kind of learning seems to be at the level of auditory cerebral cortex in the temporal lobe. This learning is rote and concrete - specified in a space of specific frequencies and temporal intervals.
PRESPEECH AUDITION. There is now a great deal of evidence that children during their first year learn to recognize the important ``sounds'' of their ambient language (Werker and Tees, 1984). The allophone-like spectro-temporal trajectories that occur frequently are recognized in fragments of various sizes. And any sound patterns that occur very infrequently or are novel tend to be ignored, ``missed'', or grouped with near neighbors that do occur frequently (that is, the phenomena justifying `categorical perception,' the `magnet effect' etc.). This clustering process or partial categorization of speech sounds takes place at a time when infants produce no words and recognize only a small number. (And they certainly know nothing about alphabets yet.)
COMPLEX PATTERN AND CATEGORY LEARNING. Speech perception is acquired like other complex auditory (or visual) patterns -- by simply storing a great many rather concrete (that is, close-to-sensory) representations of instances or tokens (or exemplars).
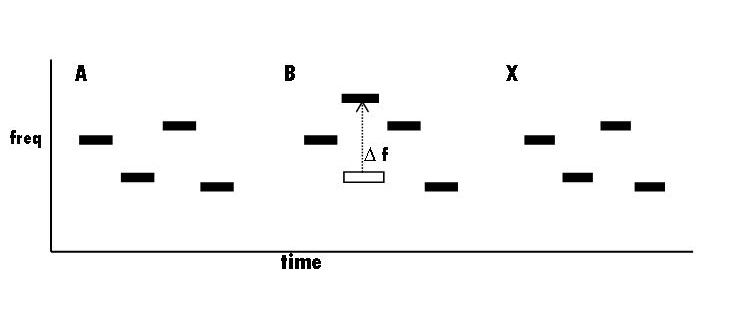
If a very complex but completely unfamiliar and novel auditory pattern is played to an adult, they will be able to recognize
very little about it. But if the pattern is repeated many times, eventually, subjects construct a very detailed, description of the pattern. Charles S. Watson did many experiments using a sequence of 7-10 brief pure tones chosen randomly from a very large set of possible tones. (The example below has 4 tones.) A complete 10-tone pattern was completed in less than a second. Such patterns are completely novel and extremely difficult to recognize. In his many experiments, Watson would typically play some random tone pattern 3 times to a subject and change the frequency of one of the tones between the A presentation and B. Then the subject has to say if X, the third pattern instance, is the same as the first or second (an ABX task). However, if a subject is given the same pattern for many trials, eventually, they learn the details of that pattern and can detect small changes (delta f) in one of the tones. That is, they learn a detailed representation for any pattern given enough opportunities to listen to it.
When we become skilled at speaking our first language, we become effective categorizers of the speech sounds, the words in our language, etc. So, abstract categories of speech sound (like letters, phonemes, syllable-types, etc.) can eventually be learned. A category is a kind of grouping of specific phenomena into classes based on some set of criteria. (Of course, a category is only remotely similar to the kind of symbol token usually assumed to provide the output of the speech perception process.
Conclusion.
My proposal is that speech perception is based on nonspeech, auditory perception. Each child learns a descriptive system of auditory features that probably differs in detail from child to child. This feature system includes both spectral and temporal dimensions. Still, this high-dimensional representation makes it possible to store large numbers of concrete, detailed records of specific utterances. This body of detailed auditory records provide (I think), the database on which linguistic categorization decisions are made.