Opie Research Group
Department of Computer Science
Indiana Univeristy

Welcome to the Opie Research Group's webpage!
You can find us in Lindley Hall 328 on the Bloomington campus.
Thanks to the National Science Foundation for supporting this research under a grant entitled "Compiler Support for Morton-Order Matrices," numbered CCR-0073491.
Distribution: click here.
Introduction
The goal of the Opie Project is to compile conventional programs in imperative languages like C, C++, Fortran, or Java operating on matrices into equivalent programs. So an Opie compiler merely transforms one program into another.
The difference is how matrices (arrays) are represented.
Traditional internal representation of matrices is in row-major (or, in Fortran, column-major) order. That is, a row (or column) occupies locations that are sequential in memory. Such locality is critical to cache performance. An important alternative is to represent matrices internally in Morton order, illustrated here for a 16x16 matrix, which stores blocks---nested recursively---in sequential memory. An Opie compiler, first, transforms archival code from row-major (analogously, column-major) onto Morton order.
{kind=link}
Knowledge of the internal representation affects the programmer's choice of algorithm. An author who seeks fast code has a natural tendancy to honor the hardware in making that choice. Today a big contraint is hierarchical memory of more and more levels: L1, L2, and L3 cache, TLBs, RAM, and paging to disk. Opie does not change the programmer's algorithm! As a corollary, it might even slow a row-traversing program.
For example, here is a graph illustrating what representation, alone, does for a classic algorithm, matrix multiplication:
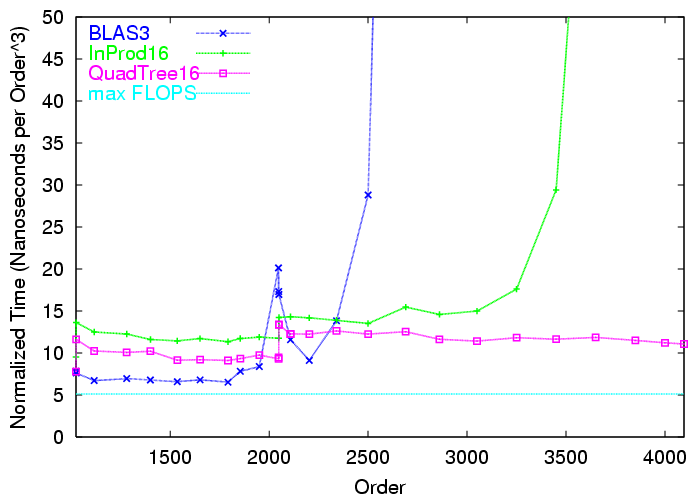
This is a plot of times to multiply NxN matrices, divided by N3. We use this quotient because it exposes the leading coefficient of the cubic polynomial of N that yields the time; ideally it is constant and close the the minimum possible. On this MIPS R10000 processor that is indicated by the flat torquoise line at the bottom. The iterative algorithm is six nested loops for a blocked matrix multiplication, the outer three loops traversing 16x16 blocks and the inner three multiplying those 8192-flop base cases. In blue, BLAS3 thrashes as soon as paging to disk becomes necessary; in red, an Arcee block-recursive algorithm has stable times. Importantly in green, a prototype Opie compilation of those same six loops onto Morton-order representation, albeit slower, introduces inner locality that postpones the disk thrashing.
Compiling
Morton order admits other algorithms, via a different paradigm of programming being developed under the sister Arcee project. Supported by Morton order internally, that family of algorithms is proving to be very fast. But as the new kid on the block, it lacks the infrastructure (libraries) from forty years of row/column-major algorithms. The goal of the Opie compilers is to transform that infrastructure (essentially) intact.
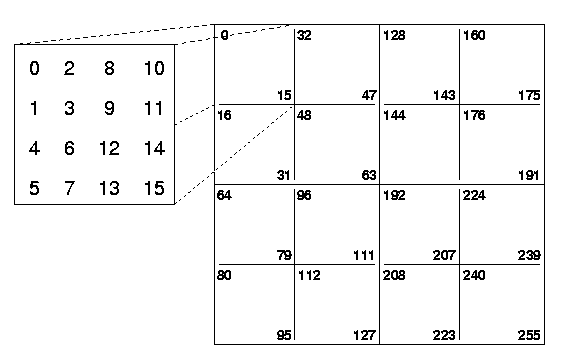
The second goal of an Opie compiler is to provide convenient syntactic support for indexing schemes that support the quadtree decomposition of matrices on which the Arcee project depends. A very useful tool is Ahnentafel indexing, illustrated here for a 4x4 matrix. Classes like Ahnentafel indices and dilated integers augment the usual ints used as cartesian, Morton, and level-order indices into binary-tree representations of vectors, quadtree representations of matrices,
{kind=link}
and---generally--- 2d-ary trees representing d-dimensional arrays.
This support will be especially useful to carry the Arcee paradigm into languages like ML, Scheme, and Haskell.
Morton-ordered matrices instrinsically provide excellent locality of reference. In addition, we advocate divide-and-conquer algorithms on these matrices. Thus it is possible to formulate elegant recursive algorithms that, by default, account for performance in the memory hierarchy, and are easy to parallelize.
"Opie"
So you're probably asking yourself, "What's an opie?" Recall that we perceive the compiler performing a transformation from certain styles of code onto another.
That makes it a Transformer ... and of course, we all know that the best Transformer® is Optimus Prime. So Optimus Prime---O.P.---is shortened to Opie, and the name stuck. And, just because, we have the above picture of everyone's favorite Autobot in all his glory. (This is from the movie ... right now, he's about to charge into the Decepticon-controlled Autobot City to save the Autobots trapped inside. He's saying "Megatron must be stopped ... no matter the cost.")
The link between Megatron and Fortran is left to the reader.
Contributors to the Opie Project:
- David S. Wise (homepage) Professor.
- Matt Carlson (homepage), REU Undergraduate.
- Steve Gabriel (homepage), PhD Student.
- Mike Rainey (homepage), REU Undergraduate.
- Jeremy Frens (homepage), Ph.D. Alumnus.
- Yuhong Gu, M.S., Alumna.
- Craig Citro (homepage), REU B.S. Alumnus.
- Gregory Alexander, REU B.S. Alumnus.
Papers:
- Rajeev Raman and David S. Wise. Converting to and from Dilated Integers. IEEE Trans. Comput. (in press). Authors' version .
- Michael A. Rainey and David S. Wise. Embedding Quadtree Matrices in a Functional Language. Submitted for publication (2004). Authors' version .
- Steven T. Gabriel. and David S. Wise. The Opie Compiler: from Row-major Source to Morton-ordered Matrices. Proc. 3rd Workshop on Memory Performance Issues (WMPI-2004), New York: ACM Press (2004 June) 136--144. Authors' version .
- Jeremy D. Frens and David S. Wise. QR factorization with Morton-ordered quadtree matrices for memory re-use and parallelism. Proc. 2003 ACM Symp. on Principles and Practice of Parallel Programming, SIGPLAN Not. 38, 10 (2003 October), 144--154. Authors' version.
- David S. Wise, Jeremy D. Frens, Yuhong Gu, and Gregory A. Alexander. Language support for Morton-order matrices. Proc. 2001 ACM Symp. on Principles and Practice of Parallel Programming, SIGPLAN Not. 36, 7 (2001 July), 24--33. Authors' version.
- David S. Wise. Ahnentafel indexing into Morton-ordered arrays, or matrix locality for free. In A. Bode, T. Ludwig, R. Wismu"ller (eds.), Euro-Par 2000 -- Parallel Processing, Lecture Notes in Computer Science 1900, Berlin: Springer (2000 August), 774-784.
- David S. Wise and Jeremy D. Frens. Morton-order matrices deserve compilers' support. Technical Report 533. Computer Science Department, Indiana University (1999 November).
- David S. Wise. Undulant block elimination and integer-preserving matrix inversion. Sci. Comput. Program 33, 1 (1999 January), 29--85. Math Review 1 653 749. Abstract only: SIGSAM Bull. 29 (1995 June), 28. Author's version.
- Jeremy D. Frens and David S. Wise. Auto-blocking matrix-multiplication, or Tracking BLAS3 performance from source code. Proc. 1997 ACM Symp. on Principles and Practice of Parallel Programming, SIGPLAN Not. 32, 7 (1997 July), 206--216. Authors' version.
Related Work:
- E. Elmroth and F. Gustavson. Applying recursion to serial and parallel QR factorization leads to better performance. IBM J. Res. Develop., 44(4):605-624, July 2000.
- S. Chaterjee, A. R. Lebeck, P. K. Patnala, and M. Thottenthodi. Recursive array layouts and fast parallel matrix multiplication. IEEE Trans. Parallel Distrib. Syst., 13(11):1105-1123, Nov. 2002.