Neural Networks in SALSA
Neural Networks
- Network of interconnected processing units. Each connection in the network has an associated weight.
- Each unit has an activation, which varies relatively rapidly. The pattern of activation across the network usually represents the network's short-term memory.
- Some of the units are designated input units. These are clamped to particular activation values when the network is presented an input pattern. Some of the units may also be designated output units; their activations represent the network's response. Some of the units may also be designated hidden units. These are units which are neither input nor output. They do not make contact with the environment and function as a place for the re-representation of input patterns, usually on the way to the output units.
- Each unit (unless clamped) repeatedly updates its activation. It first calculates its current input from all of the other units that it is connected to. This is the sum of the inputs from each other unit. The unit then calculates its new activation, based on the input, and possibly its old activation.
- Weights in the network are changed relatively slowly. They represent the network's long-term memory. The way weights change depends on the network's learning algorithm. Weight changes are usually Hebbian; that is, they are proportional to the activations of the units on either end of the connection. In error-driven learning (for example, back-propagation) the weight changes are based on the network's error, a function of the difference between its output for a given input pattern and a target, what the network should have output for that pattern.
- The network is trained on the basis of a set of training patterns (inputs and sometimes targets). Later it may respond appropriately to novel input patterns; that is, it may generalize.
Neural Networks for Reinforcement Learning
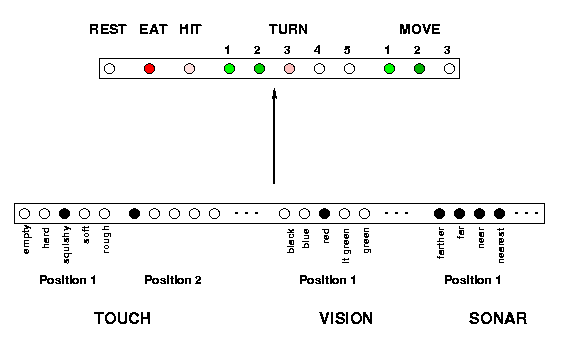
We can replace the lookup table for Q-learning with a neural network. Each state is represented by a pattern over the input units; each input unit represents a sensory input feature. Each action is represented by a single output unit. The network's stored Q-values for the actions associated with a given state are found by activating the input units with the pattern representing that state and observing the activations of the output units. Each output unit's activation represents the Q-value for the corresponding action in the given state. The Q-values are actually stored in the network's weights.
During Q-learning, the agent selects an action in the current state, makes a response, and receives a reinforcement from the environment. A new Q-value for the state-action pair is calculated on the basis of the reinforcement and the stored maximum Q-value for the next state (found by running the network) using the first update equation here. This value is treated as the target for the output unit corresponding to the selected action, and the weights in the network are updated using error-driven learning (the error is the difference between the target and the network's output). The network's learning rate is a number between 0 and 1, corresponding to eta in the second update equation. The learning rate controls the rate at which the weights are updated.
Representation