ASR as Bayesian inference
- The noisy channel model
-
The noisy sentence we "observe" is the result of an underlying (source) representation of a sentence passed through a noisy channel.
- Given an observed sentence, we want to infer the most likely underlying sentence
that generated it.
- An observed sentence is a sequence of observations:
`O = o_1, o_2, ..., o_t`.
- An underlying (source) sentence is a sequence of words:
`W = w_1, w_2, ..., w_n`.
- The problem:
`hat W = argmax_{W in L} P(W|O)`
- Bayes' Law: `P(x|y) = (P(y|x)P(x))/(P(y))`
- The problem rewritten:
`hat W = argmax_{W in L} P(W|O) = argmax_{W in L} (P(O|W) P(W)) / (P(O)) =
argmax_{W in L} P(O|W) P(W)`
- The language model: `P(W)`
- The acoustic model: `P(O|W)`
- Decoding (search)
Feature extraction / signal processing
- Acoustic waveform sampled into a set of overlapping frames of equal lengths
(10, 15, or 20 ms)
- Each frame transformed to a set of spectral features (around 39)
using discrete Fourier transform
- Frequencies mapped on a scale more representative of human audition: the mel scale
- A final transformation: cepstrum: spectrum of log of normalized spectrum —
effectively separates out source and filter in signal
- Cepstral coefficients, energy features, change features for cepstral coefficients and energy: MFCC (mel frequency cepstral coefficients)
Acoustic model
- A hidden Markov model for each word containing submodels for each phone
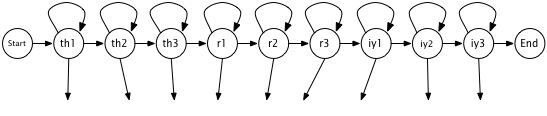
- Figuring the emission probabilities in the HMMs:
Gaussian mixture models
- Gaussians as probability density functions; each Gaussian characterized by a mean
and a variance.
- Calculating the value of a single observation feature given a particular HMM state
- The training problem: computing the and mean variance for the Gaussians for each
HMM state using the iterative Baum-Welch algorithm
- Multivariate Gaussians: assigning a probability to a 39-valued vector
- Modeling observation likelihood with a weighted mixture of multivariate Gaussians
Decoding
- Assigning probabilities to word sequences
- Viterbi algorithm: returns the most state sequence for a given set of HMMs
- Efficient search through the space of possible word sequences (HMMs)
- Beam search and pruning





