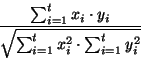This experiment examined the comparative performance of WordSieve and TFIDF at matching a document, when seen out of context, to its original search task, described by a term vector representation of the search phrase. The search phrase vectors were compared to the vectors produced by WordSieve profiles and TFIDF.
Seven subjects separately searched the WWW for 20 minutes each. During that time, they were asked to perform two tasks. For the first ten minutes, they were told to load into their browser pages about ``The use of Genetic Algorithms in Artificial Life Software.'' After ten minutes, they were asked to search for information about ``Tropical Butterflies in Southeast Asia.'' Every document they accessed through the browser was automatically recorded. The HTML tags were stripped, as well as punctuation, but no filtering was done on the pages accessed. ``PAGE NOT FOUND'' pages and pages which contained advertisements were not filtered out. Thus the data collected represents a realistic sampling of the kinds of pages that an Intelligent Agent must handle when observing a user accessing the WWW. To provide an evaluation criterion, documents which did not pertain to the user's search (such as ``PAGE NOT FOUND'' documents) were then hand-tagged as ``noise'' documents, and the other documents were hand tagged as either belonging to the genetic algorithm or the butterfly task. These tags were not available to WordSieve.
Users accessed an average of 124 documents per 20 minute session. On average, they accessed 69 ``noise'' documents and 54 relevant documents. A total of 590 different documents were accessed, 381 of which were determined to be relevant. There were 135 documents which were accessed by more than one user, 88 of which were determined to be relevant documents.
During the user's browsing, the documents were stored. This data was then run through the WordSieve in a series of ``simulated'' browsing sessions. The sessions were simulated only in the sense that the user was not actually at the browser; the data was processed by WordSieve in the same order in which the user accessed it, and no pages were omitted. To simulate multiple task changes, a single simulated browsing session consisted of passing data from one user session through WordSieve three times. Thus information presented to the system was as if the user alternated searching for information about genetic algorithms, and information about butterflies three times, for ten minutes each.
Having built up a context model with WordSieve, a vector for each relevant document in each simulated run was computed by running the document through an empty level 1 and multiplying the resulting node values by their values in the other two levels. The vector for the TFIDF was computed as per Salton [17]. For each word in the document, the weights of each word in the vector were defined by equation 2.
Then, each resulting vector was compared to the original query. Similarity to the original query was calculated via the cosine similarity metric shown in equation 3 [17].
In all cases, when computing vectors and doing comparison, the algorithms only had access to the documents in one user's session. Each user's session was treated independently.