


Next: Layers 2 and 3
Up: WordSieve
Previous: WordSieve
The bottom layer (1) performs initial processing on the text stream. Through a competitive learning process,
this layer assigns the units in this layer to the most frequently occurring words. In
the current implementation, this layer contains 150 units, so it can be
sensitive to only 150 unique words at a time.
The number of units in this layer is significant, because
it is a competitive network. If there are too many units, there is not enough
competition and it will not identify the correct words. If there are too few
units, the competition is so great that it will not learn all the words needed.
The algorithm appears to work well under a reasonably
large range of layer sizes, but we have not yet conducted a comprehensive analysis
of the effects of changing the layer size.
Words are assigned to units as follows: Each of the 150 units is associated
with a unique word. As the documents are read, each term passes through the
bottom layer in the order in which it occurs in the document. If the word is
already associated with a unit in the layer, the excitement of that unit is
increased by a value 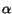 (see below). If the word is not associated with
any term, it is given a chance to ``take over'' a randomly chosen unit.
The term takes over the chosen unit with a probability of
0.0001(e-100)2, where e is the excitement of the unit and has a
range of 0 to 100. The chance of ``taking over'' the unit thus decreases with
the excitement of that unit. Also, the values of all the units decay at a
rate
(see below). If the word is not associated with
any term, it is given a chance to ``take over'' a randomly chosen unit.
The term takes over the chosen unit with a probability of
0.0001(e-100)2, where e is the excitement of the unit and has a
range of 0 to 100. The chance of ``taking over'' the unit thus decreases with
the excitement of that unit. Also, the values of all the units decay at a
rate 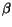 .
.
Next: Layers 2 and 3
Up: WordSieve
Previous: WordSieve
Travis Bauer
2002-01-25